
L’ empreinte numérique des pays pauvres
La place et les rôles qu’ont joués les civilisations dans l’Histoire déterminent, pour l’essentiel, la marche du monde contemporain. À travers les âges, les peuples ont utilisé diverses méthodes d’écriture et d’archivage dans le but de transmettre leurs histoires aux générations futures. Très souvent, l’efficacité de ces méthodes a été déterminante dans la perception et l’influence de cette civilisation sur le reste du monde.
Avec l’avènement d’internet, je pense que les empreintes numériques laissées par les populations suivant leurs conditions socioéconomiques auront un impact sur la place que celles-ci occuperont, ou sur le rôle qu’elles auront à jouer sur la scène mondiale. Par exemple, grâce au numérique, la guerre en Syrie est devenue l’un des conflits les plus documentés que l’humanité ait connu.
Qu’est-ce que l’ empreinte numérique ?
Tout comme l’empreinte carbone, l’empreinte numérique est l’ensemble des « traces et des marques que nous laissons derrière nous quand nous naviguons sur Internet » (Internet Society). Ces données concernent autant de domaines que de langues à travers le monde.
À mon sens, l’ empreinte numérique reste quand même une expression assez générique. Elle ne devrait pas, exclusivement, concerner les données générées par les seuls internautes mais aussi celles produites par des institutions ou des gouvernements, notamment avec l’open data.
Aujourd’hui, la surproduction de données numériques, communément appelées big data, permet le développement des techniques « d’apprentissage profond », ou deep learning. Ce qui signifie qu’il y aura de plus en plus de produits et de services dont la qualité et l’efficacité dépendra des données que produiront les internautes. Évidemment, la quantité de ces données ou empreintes numériques sera différente suivant l’ethnie, le pays ou le continent. Cela, tout simplement parce que la répartition de l’accès à internet et aux TIC (Technologies de l’information et de la communication) reste assez inéquitable à l’échelle planétaire.
Même si aujourd’hui les données numériques sont générées par des processus assez standards, il n’en demeure pas moins qu’elles restent très variées dans leurs significations suivant les communautés. Ce qui, à mon avis, aura des conséquences sur la manière dont ces données seront interprétées par les algorithmes des géants du numérique.
Quelques exemples
Pour illustrer mes propos nous allons découvrir quelques services qui fonctionnent plus ou moins bien selon les données qu’ils reçoivent.
Les premiers sont les services de traduction en ligne. Intéressons-nous à Google Traduction, l’un des plus célèbres. Il faut savoir qu’il existe plusieurs méthodes de traduction en ligne. Google utilise la technique de la Traduction Automatique Statistique. Grosso modo, pour traduire un texte vers une autre langue, Google a besoin d’au moins deux millions de mots pour un domaine spécifique et bien plus pour un domaine général vers la langue cible. Vous trouverez tous les détails sur cette technique de traduction ici.
Donc, le résultat d’une traduction sera plus ou moins correct à partir du moment où la machine fera correspondre un nombre de mots assez conséquent entre les langues choisies, dans un sens de traduction comme dans l’autre.
J’avoue qu’en faisant mes recherches, je me suis demandé : mais où est-ce que Google trouve autant de mots dans les langues qu’il prend en charge? Sachez qu’il puise cette documentation au niveau des Nations Unies.
J’ai essayé de traduire un poème d’Emily Dickinson: To make a prairie. D’abord du français vers le haoussa (ma langue maternelle 🙂 ) et de l’anglais vers le français. Et bien les traductions étaient bien meilleures dans le second cas que dans le premier. Parce que tout simplement, il n’y a pas autant de références de mots sous forme de données numériques dans la langue haoussa que dans les deux autres langues.
C’est vrai que le haoussa n’a pas un lexique aussi large que l’anglais ou le français. Néanmoins, on voit que certains mots, bien qu’existant en haoussa, n’ont pas suffisamment de références numériques pour que la traduction en ligne les prennent en compte. C’est par exemple le cas du mot « rêverie ». Le manque de mots modifie aussi le sens de certaines phrases : en français, le vers « Si vous êtes à court d’abeilles » devient en haoussa « Si vous échappez aux abeilles » 😀
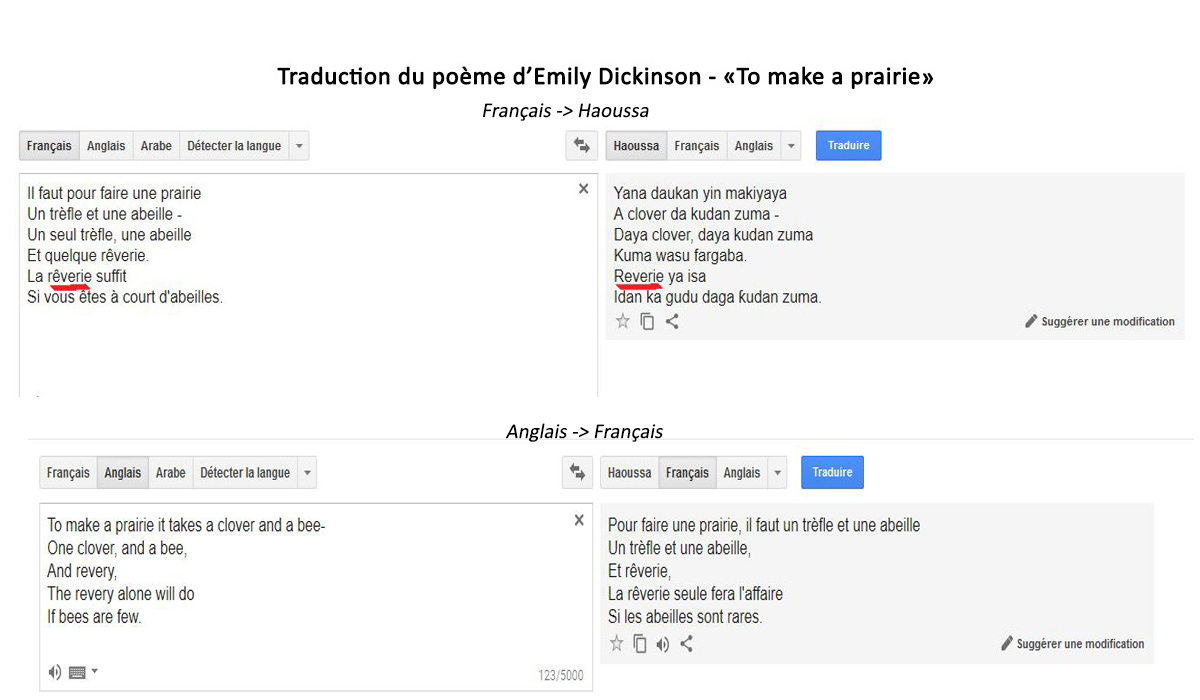
Les empreintes numériques qui existent dans cette langue sont donc faibles. On remarque que plus un pays a une faible connectivité à internet et un faible accès aux TIC, plus les services web construits dans et pour les langues utilisées dans ce pays auront un train de retard par rapports à ceux écrits dans les langues de nations plus avancées.
Un deuxième exemple est celui des services météos. Sur cette capture d’écran on voit comment différents services de météorologie interprètent les températures. La première fois que j’ai vu ces informations, j’ai souri. Évidemment on remarque tout de suite que ces services se trompent sur le ressenti de la température par les populations locales. On peut lire qu’il fait « extrêmement chaud » à 37 ° C, ce qui n’est absolument pas le cas : ici on dit qu’il « commence à faire un peu chaud » à une telle température. Il commencera à faire effectivement chaud lorsque les températures seront supérieures à 38°C et « extrêmement chaud » à 45°C ou plus.
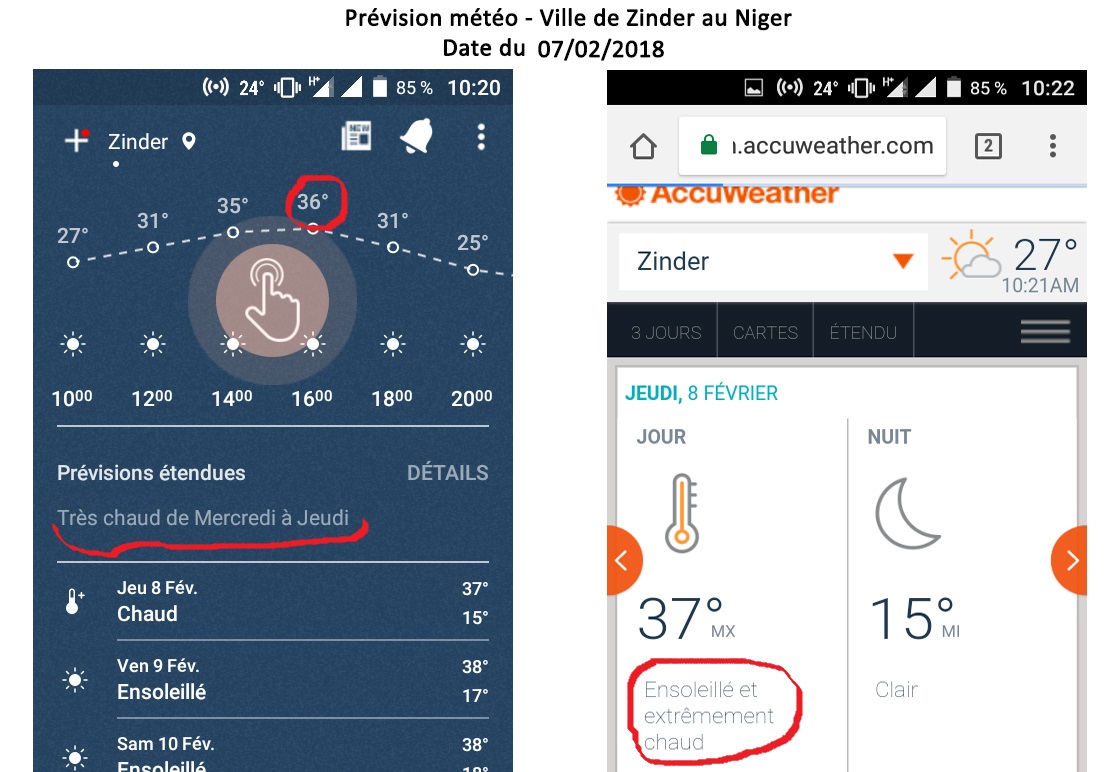
C’est vrai que cette fois-ci, les données qu’utilisent les services météorologiques ne proviennent pas de l’ empreinte numérique des internautes qui l’utilisent, en tout cas pour l’essentiel. En effet, les constructeurs des applications de météo ne viennent, visiblement, pas de pays où il fait 37°C très souvent. Mais la mauvaise interprétation de ces informations par rapport à une population donnée risque d’avoir un effet dominos, potentiellement dangereux, sur un ensemble de services dépendant de ces prévisions. Non seulement l’empreinte numérique ne sera pas fiable, mais en plus elle pourrait s’avérer dangereuse.
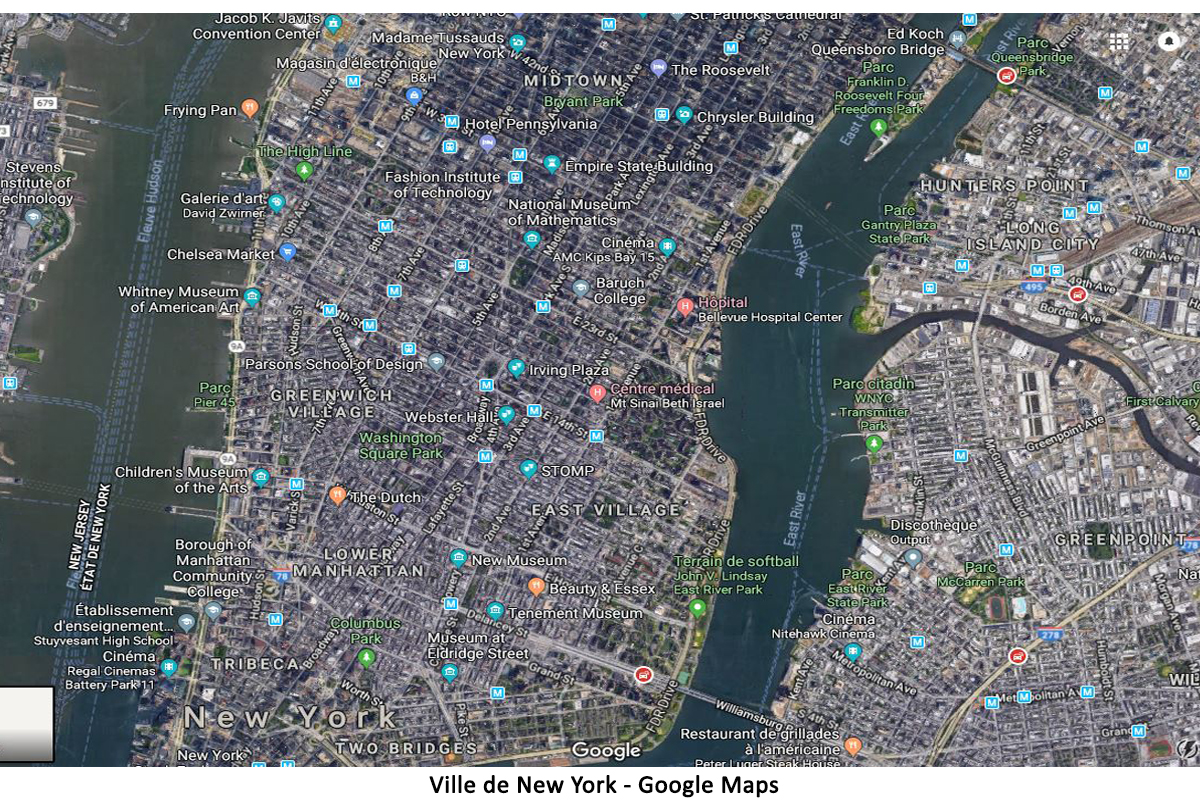
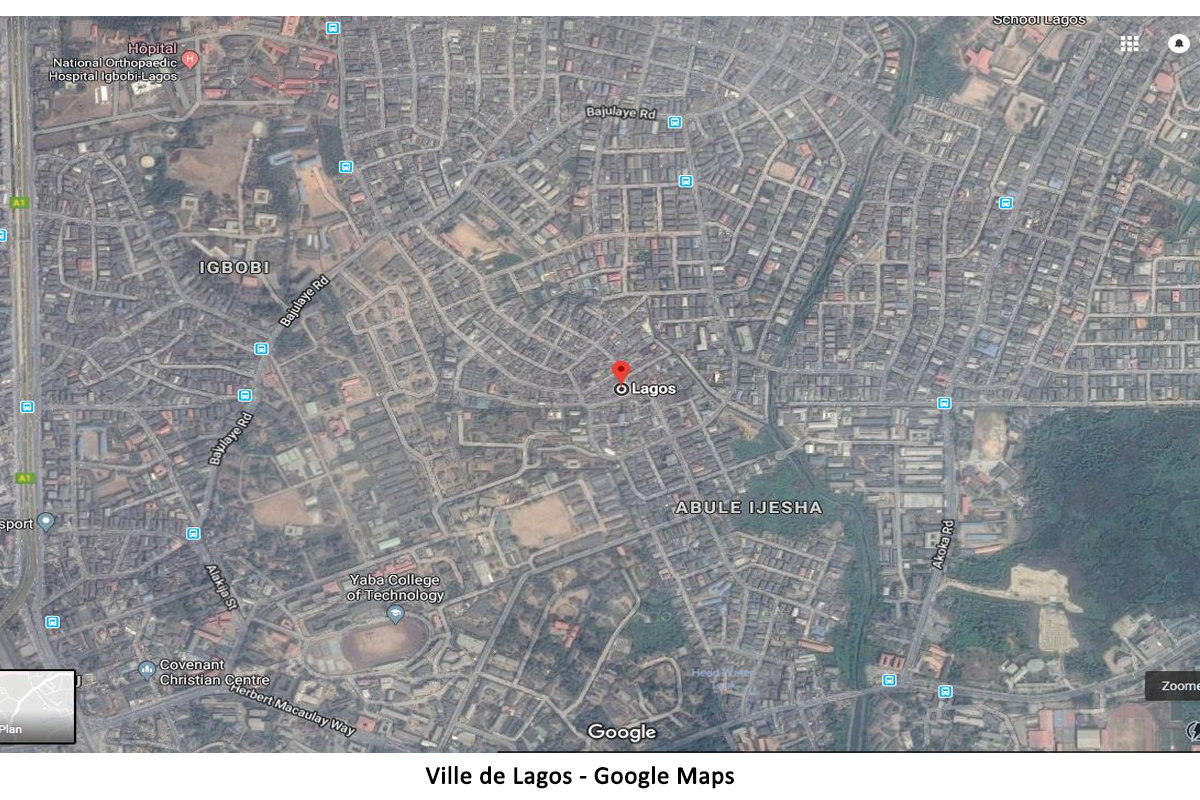
Le troisième et dernier exemple que je vous propose concerne les services de géolocalisation en ligne. Là encore, on constate que le nombre de renseignements utiles sur une carte dépend de la facilité d’accès à internet des habitants qui y vivent. C’est sûr que ce n’est pas le seul critère, mais il reste néanmoins déterminant.
Les images ci-dessous montrent respectivement les villes de New York (8,5 millions d’habitants) et de Lagos (21 millions d’habitants). Dès que l’on zoome un peu (à 500 m), on voit tout de suite qu’il y a une vraie différence. Pour une même échelle, il y a moins d’informations disponibles pour la ville de Lagos que pour New York.
En conclusion
Je dirais que l’empreinte numérique générale des pays technologiquement avancés est pour le moment beaucoup plus conséquente dans beaucoup de domaines. On voit par exemple que les assistants vocaux ne sont, pour la plupart, disponibles que dans les langues occidentales, de même que l’écrasante majorité des TIC et autres outils numériques.
J’espère que la standardisation des modèles actuels tiendra compte de la diversité des techniques, des langues et de bien d’autres caractéristiques qui ont façonné l’histoire de l’humanité des siècles durant. Cet héritage ne doit pas être englouti au nom de la nouvelle ère numérique.
Commentaires